Introducing o11y-bench: an open benchmark for AI agents running observability workflows
Summary
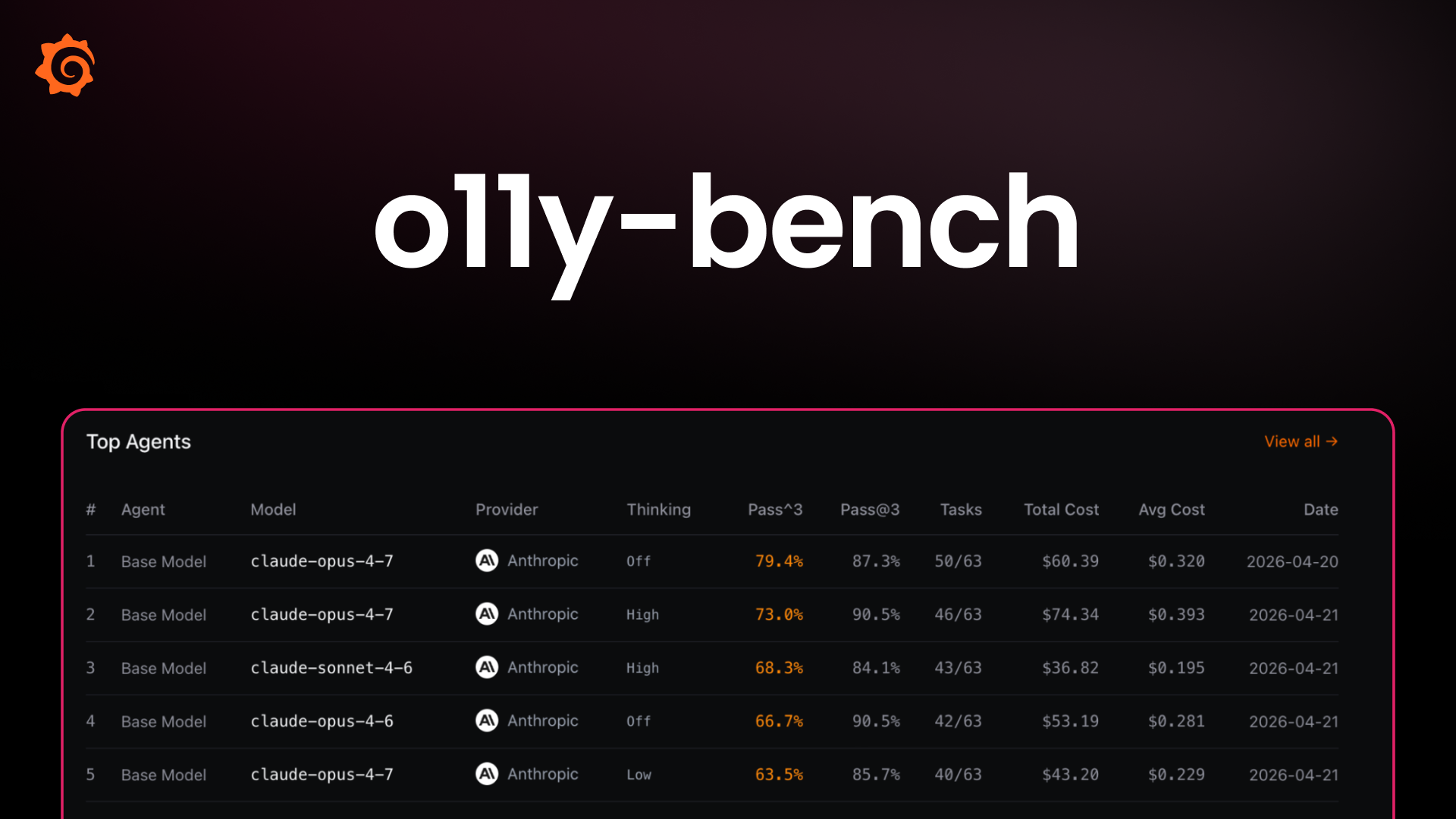
Grafana has introduced o11y-bench, an open-source benchmark designed to evaluate the effectiveness of AI agents performing complex observability tasks, such as incident investigation and dashboard management. By running agents against a real Grafana stack, the benchmark assesses performance based on verifiable ground-truth outcomes rather than just linguistic accuracy. This provides a standardized way to measure the reliability and consistency of AI models in high-stakes, real-world monitoring environments.
Read the Original Article
This article originally appeared on Grafana Labs blog on Grafana Labs.
Read Full Article on Original Site


